
Back to Blog
Real-Time Data Engineering
Why Are Databases Underestimated in Machine Learning (Part Two)?
Comparing Tacnode against traditional fragmented ML stacks.
Comparing Tacnode against traditional fragmented ML stacks.
TL;DR: The typical ML stack — data warehouse + feature store + vector database + streaming infrastructure — creates compounding operational overhead: data copying, schema propagation, debugging across independent logs. Tacnode Context Lake consolidates these into a single system with unified storage and infrastructure. The most powerful capability is in-database feature engineering: features computed as SQL over live data, eliminating training-serving skew by construction.
In Part One, we explored why databases are overlooked in ML workflows. In Part Two, we examine the practical consequences of the fragmented stack and how consolidation addresses them.
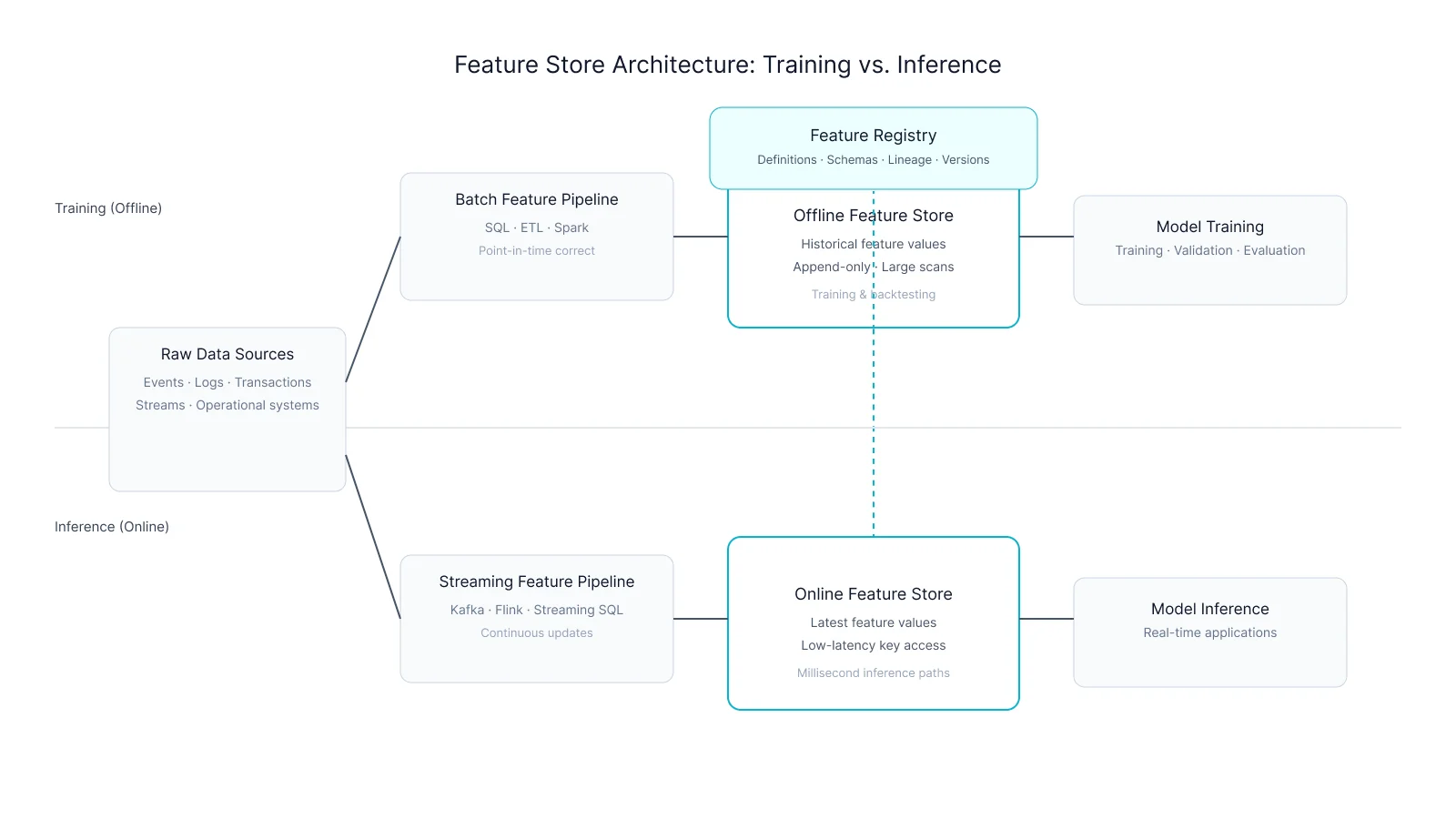
The typical ML stack includes: a data warehouse for historical data, a feature store for serving features, a vector database for embeddings, and streaming infrastructure for real-time signals. Each component adds operational overhead.
Every seam between systems is a potential point of failure. Data must be copied, synchronized, and reconciled. Schema changes must propagate across multiple systems. Debugging requires tracing through independent logs.
The operational burden compounds over time. Teams that started with simple integrations find themselves maintaining complex orchestration layers. The ML platform becomes a patchwork of band-aids.
Tacnode Context Lake consolidates these capabilities in a single system. Historical data, computed features, and vector embeddings share unified storage. Ingestion, transformation, and serving share unified infrastructure.
The benefits are multiplicative: simpler operations, consistent guarantees, lower latency, and reduced cost. Teams can focus on ML, not infrastructure maintenance.
Perhaps the most powerful capability is in-database feature engineering. Features are computed as SQL queries over live data, served directly from the database, with no ETL in between.
This eliminates the gap between batch training features and online serving features. Training and inference use the same computation, the same data, the same guarantees. Training-serving skew becomes impossible by design.
The fragmented ML stack was a necessary evolution. Each component solved a real problem. But the cost of fragmentation has become untenable as ML moves from experiments to production systems.
Consolidation is the path forward. Databases that understand ML workloads—Context Lakes—are the foundation for the next generation of ML infrastructure.
Book a demo and discover how Tacnode can power your AI-native applications.
Book a Demo